❡ CTF 学习笔记
❡ CTF
❡ 定义
CTF 就像一场 “黑客版的寻宝游戏”,参赛者通过破解密码、挖漏洞、逆向程序等技术手段,在虚拟世界里找到隐藏的 “flag”(一串特定字符),谁找得快、技术强谁就赢。
❡ 竞赛模式
解题模式(Jeopardy)
* 核心机制 *:通过解决安全技术题目获取 flag,按题目分值和解题时间排名,常见于线上选拔赛。
* 动态积分规则 *:题目初始分值随解题人数增加而递减,前三名(一血、二血、三血)获得额外奖励分。
* 题型分类 *:Web 渗透、逆向工程、密码学、安全杂项(MISC)、二进制漏洞(PWN)等。
玩法:像做试卷,题目分类型(如密码破译、逆向工程、Web 漏洞等),解出题目后提交隐藏的 flag 就能得分。
特点:
- 题目难度越高分越多,但解题人数越多分越少(动态积分)。
- 适合线上赛,比如预选赛,团队可自由组队,拼脑力和技术积累。
举例:给你一个网站,找 SQL 注入漏洞拿 flag,类似 “黑客版奥数题”。
攻防模式(Attack-Defense) (黑客版真人 CS**)
* 核心机制 *:各队伍拥有相同漏洞的服务器(GameBox),攻击对手服务得分,修补自身漏洞防御扣分,实时对抗性强。
* 计分规则 *:每轮得分取决于攻击成功次数和防御状态,服务宕机将扣分。
* 特点 *:高强度持续 24-48 小时,考验团队协作和体力。
ADP 攻防增强模式
一句话总结就是 ==“黑客版的一题两吃”==:每个题目只需完成一次攻击(拿 flag)和一次防御(修漏洞),做完就扔,不用反复折腾。
❡ 举个栗子🌰:
假设题目是一个带漏洞的网站,ADP 模式下你要做两件事:
1️⃣ 攻击:找到漏洞(比如 SQL 注入),拿到 flag 提交得分(类似解题模式)。
2️⃣ 防御:给漏洞打补丁(比如过滤 SQL 语句),上传补丁到平台验证,确认修好后得分。
这题就算完事了! 之后不用再管它,专心搞其他题目就行。
❡ 和传统攻防(AwD)的区别:
对比项 传统攻防(AwD) ADP 攻防增强 攻击方式 全程用脚本批量攻击对手,抢 flag 刷分 每个题只需攻击一次,提交 flag 就停手 防御方式 边修漏洞边防对手攻击,服务崩了会疯狂扣分 修好漏洞并验证通过后,这题永远不扣分了 选手压力 熬夜修漏洞 + 写攻击脚本,像打仗一样累 像做作业,一题两步骤,做完就躺平 主办方压力 要维护几十台服务器,防止被选手打崩 题目环境用完就删,省电省服务器 ❡ ADP 的核心优势:
- 选手省力:不用写自动化脚本,不用盯着服务是否崩溃,专注解题和修漏洞本身。
- 主办方省钱:题目环境用完就销毁,不用扛住几百个队伍的持续攻击。
- 题目灵活:比赛过程中可以随时换题(比如旧题下线,新题上线),增加新鲜感。
❡ 适合谁玩?
- 新手友好:适合刚接触攻防模式的小白,不用学写攻击脚本。
- 中小型比赛:比如企业内训、高校校赛,运维成本低。
- 专精 Web/PWN 的选手:ADP 通常只出这两种题型,其他方向(如逆向、密码学)不参与。
总结:ADP 就是 **“简化版攻防”**,把持续对抗拆成单次任务,让选手和主办方都轻松点~
混合模式(Mix) (解题 + 攻防二合一)
* 机制 *:结合解题与攻防,解题获取基础分后进入攻防对抗,分数动态增减。
* 典型赛事 *:iCTF 国际赛、RealWorld CTF(RWCTF)。
- 其他衍生模式
*KoH(抢占山头)*:攻击并控制中央服务器,写入队伍标识后防御加固,定期判定得分。
RW(真实世界):模拟真实漏洞利用,比如攻击物联网设备。
* 战争分享模式 *:队伍互相出题 + 解题 + 分享思路,综合评分。
*AI 自动化(RHG)*:编写自动化程序(bot)全自动挖掘漏洞并提交 flag。
❡ CTF 主要题型及考察重点
1 | |
❡ CTF 学习路线
初期基础
*Web 开发 *:HTML/CSS/JS、PHP+MySQL 开发动态网站,掌握基础漏洞原理(如 SQL 注入)。
* 工具入门 *:Burp Suite 抓包改包、Python 脚本编写(requests 库)。
中期漏洞专项
* 核心漏洞 *:SQL 注入、文件上传、命令执行(RCE)、XSS/CSRF。
* 靶场练习 *:sqli-labs、upload-labs、DVWA。
后期综合实战
* 赛事参与 *:BUUCTF、CTFHub 等平台刷题,参与校赛 / XCTF 联赛。
* 知识扩展 *:逆向工程(《加密与解密》)、二进制漏洞(《IDA Pro 权威指南》)。
❡ 比赛形式
CTF 比赛一般分为线上赛和线下赛。通常来说,线上赛多为 初赛 ,线下赛多为 决赛 ,但是也不排除直接进行
❡ 线上
选手通过主办方搭建的比赛平台在线注册,在线做题并提交 flag,线上比赛多为解题模式,攻防模式较为少见。通常来说对于长时间未解出的题目,主办方会酌情给出 == 提示 ( Hint )== 来帮助选手做题。
❡ 线下
选手前往比赛所在地,现场接入比赛网络进行比赛,线下多为 AWD 模式,近年来随着比赛赛制的不断革新,线下赛也会出现多种模式混合进行,例如结合解题 + AWD ,解题 + RW 等等
❡ 题目类型
在 CTF 中主要包含以下 5 个大类的题目,有些比赛会根据自己的侧重点单独添加某个分类,例如 == 移动设备(Mobile) , 电子取证(Forensics) == 等,近年来也会出来混合类型的题目,例如在 Web 中存在一个二进制程序,需要选手先利用 Web 的漏洞获取到二进制程序,之后通过逆向或是 Pwn 等方式获得最终 flag
❡ Web
Web 类题目大部分情况下和网、Web、HTTP 等相关技能有关。主要考察选手对于 Web 攻防的一些知识技巧。诸如 == SQL注入 、 XSS 、 代码执行 、 代码审计 == 等等都是很常见的考点。一般情况下 Web 题目只会给出一个能够访问的 URL。部分题目会给出附件
❡ Pwn
Pwn 类题目重点考察选手对于 == 二进制漏洞的挖掘和利用 能力,其考点也通常在 堆栈溢出 、 格式化漏洞 、 UAF 、 Double Free == 等常见二进制漏洞上。选手需要根据题目中给出的二进制可执行文件进行逆向分析,找出其中的漏洞并进行利用,编写对应的漏洞攻击脚本 ( Exploit ),进而对主办方给出的远程服务器进行攻击并获取 flag 通常来说 Pwn 类题目给出的远程服务器信息为 nc IP_ADDRESS PORT ,例如 nc 1.2.3.4 4567 这种形式,表示在 1.2.3.4 这个 IP 的 4567 端口上运行了该题目
❡ Reverse
Re 类题目考察选手 逆向工程 能力。题目会给出一个可执行二进制文件,有些时候也可能是 Android 的 APK 安装包。选手需要逆向给出的程序,分析其程序工作原理。最终根据程序行为等获得 flag
❡ Crypto
Crypto 类题目考察选手对 密码学 相关知识的了解程度,诸如 RSA 、 AES 、 DES 等都是密码学题目的常客。有些时候也会给出一个加密脚本和密文,根据加密流程逆推出明文。
❡ Misc
Misc 意为杂项,即不包含在以上分类的题目都会放到这个分类。题目会给出一个附件。选手下载该附件进行分析,最终得出 flag。
常见的题型有图片隐写、视频隐写、文档隐写、流量分析、协议分析、游戏、IoT 相关等等。五花八门,种类繁多。
❡ 刷题网站
❡ CTFHub
❡ Misc
❡ 流量分析
❡ 数据库流量
❡ Mysql 流量
服务端回一个 Response OK , 至此,登录验证就算是完成啦~
后面客户端向服务端发起查询请求:
==select @@version_comment limit 1==
注意得选择分组字节流才行
注意:搜索时要这样才行 ==ctfhub {== 不然找不到。
❡ 协议流量分析
- ICMP-data
注意:tshark - r 「xxx」 -Y 「相关筛选命令」 -T fields -e data > xxx
关键参数:
- -Y 「icmp && icmp.type==8」:过滤 ICMP 类型为 8(Echo Request)的包 。
- 这边等于 0 和 8 都可以,8 代表请求包,0 代表应答包
- -T fields -e data:仅输出 data 字段的十六进制内容 。
- flag.txt:将结果重定向到文件。
常见 CTF 题型分析
单向传输(Type 8):
Flag 数据通过客户端发送的多个请求包传输(如每个包携带一个字符)。
解法:过滤 Type 8 并提取 data。
双向传输(Type 8 + Type 0):
Flag 可能分散在请求和响应包中(需同时分析两者)。
解法:过滤 icmp(不限制 Type),再根据包方向(ip.src/ip.dst)分类处理。
隐蔽回传(Type 0):
恶意程序通过响应包将敏感数据回传给攻击者(如数据外泄)。
解法:过滤 Type 0 并提取 data。
总结
- Type 8 vs Type 0:取决于 Flag 数据的传输方向(谁发送的包)。
- CTF 经验法则: 如果题目提示 “客户端发送了异常 Ping 包”,优先用
Type 8;若提示 “服务器返回了异常应答”,则用Type 0。
python 代码
1 | |
- ICMP-Length
1 | |
❡ 彩蛋
❡ 首页
在 FuzzDomain 工具中,{fuzz}.ctfhub.com 的设计核心是自动化生成测试目标。具体来说:
- 动态占位符作用
- {fuzz} 是一个动态替换标记,相当于批量操作的 "通配符"。工具会从您指定的字典文件(图中路径 Dicwww.txt)中逐行读取内容,将每一行文字替换到 {fuzz} 的位置,生成如 www.ctfhub.com、api.ctfhub.com 等完整域名进行探测。
- 安全测试实战场景
- 这种设计特别适用于 CTF 竞赛 / 渗透测试中:假设攻击者想找出目标网站(如 ctfhub.com)隐藏的子域名,但无法穷举所有可能性。通过加载包含常见子域名字段的字典(如 admin、test、dev 等),工具可自动化生成并验证数千种组合,快速定位有效域名。
- 扩展性设计
- 界面下方的字符规则 pqrstuvwxyz0123456789 Min 1 Max 3 表明:除了使用预设字典,工具还支持按字符规则自动生成测试内容。例如当勾选该规则时,会自动生成 1-3 位包含指定字符的随机组合(如 p1、2qr 等),与 {fuzz} 配合实现双重探测策略。
这种 {占位符}+ 字典 / 规则的组合方式,在保证测试覆盖率的同时大幅提升效率,是网络安全工具中常见的设计范式
1 | |
❡ 彩蛋
❡ 题目入口(该题需要之前的题目提交 flag 后不关闭环境,但是我这边提交后自动关闭环境没有办法实现)
❡ WriteUp
❡ 工具
在 CTFHub 工具 页面翻到最后发现 egg
❡ 赛事
❡ 真题
❡ 投稿提交
https://github.com/guyoung/CaptfEncoder 或者使用随波逐流即可
flag[36:42]:a5f3a8
https://writeup.ctfhub.com/Other/ 投稿说明 /eaed3abd.html
AES 解密:http://tool.chacuo.net/cryptaes
❡ Web
❡ 目录遍历
知识点
目录遍历是 web 中常见的基础操作,我们通常会通过目录的遍历来发现是否存在对我们有用的信息。
❡ PHPINFO
- PHPinfo:输出 PHP 当前状态的大量信息,包含了 PHP 编译选项、启用的扩展、PHP 版本、服务器信息和环境变量(如果编译为一个模块的话)、PHP 环境变量、操作系统版本信息、path 变量、配置选项的本地值和主值、HTTP 头和 PHP 授权信息 (License)。
- phpinfo () 同时是个很有价值的、包含所有 EGPCS (Environment, GET, POST, Cookie, Server) 数据的调试工具。
❡ 备份文件下载
❡ 网站源码
- 知识点
- 常见的网站源码的文件名有:『web』, 『website』, 『backup』, 『back』, 『www』, 『wwwroot』, 'temp’等等。
- 常见的网站源码备份文件后缀有:『tar』, 『tar.gz』, 『zip』, 'rar’等等。
先使用 /www.zip 等给的不同来试,发现只有 /www.zip 有东西,而且直接打开还没有信息,只能网站打开才行。
❡ bak 文件
bak 文件泄露
有些时候网站管理员可能为了方便,会在修改某个文件的时候先复制一份,将其命名为 xxx.bak。而大部分 Web Server 对 bak 文件并不做任何处理,导致可以直接下载,从而获取到网站某个文件的源代码
得加入 /index.php.bak 尤其是最后面的.bak 才行
❡ vim 缓存
vim 交换文件名
- 在使用 vim 时会创建临时缓存文件,关闭 vim 时缓存文件则会被删除,当 vim 异常退出后,因为未处理缓存文件,导致可以通过缓存文件恢复原始文件内容
- 以 index.php 为例:
- 第一次产生的交换文件名为 .index.php.swp
- 再次意外退出后,将会产生名为 .index.php.swo 的交换文件
- 第三次产生的交换文件则为 .index.php.swn
vim 一旦异常退出就会生成 swp 文件,且是隐藏文件。隐藏文件要加点,首页也说了 flag 在 index.php 源码中 所以 /.index.php.swp 直接下载。
❡ .DS_Store
- .DS_Store 是 Mac 下 Finder 用来保存如何展示文件 / 文件夹的数据文件,每个文件夹下对应一个。
- 如果开发 / 设计人员将.DS_Store 上传部署到线上环境,可能造成文件目录结构泄漏,特别是备份文件、源代码文件。
- 在发布代码时未删除文件夹中隐藏的.DS_store,被发现后,获取了敏感的文件名等信息。
下载后打开之后得用 linux 中的 cat 查看并且再用 URL 接着执行查看即可。
❡ Git 泄露
❡ BUUCTF
❡ Web
❡ [极客大挑战 2019] EasySQL
❡ 思路
找输入点、试闭合符、构造万能密码
万能密码构造公式
1
2
3
4
5
6
7SQL' or 1=1 #
-- 或带闭合的版本(如本题用`' or true #`)
万能密码构造公式
SQL
' or 1=1 #
-- 或带闭合的版本(如本题用`' or true #`)进阶操作 若过滤了空格用
/**/代替,过滤or用||连接符等工具使用 HackBar 直接修改 URL 参数发送请求(GET 传参用
%23代替#)
❡ Crypto
❡ 一眼就解密
❡ MD5
md5 在线解密破解,md5 解密加密
❡ Url 编码
❡ 看我回旋踢
synt=flag
❡ 摩丝
❡ password(一开始有点懵,算是一种 iq 题)
判断出是 10 个数,数字占 8 个,那么就从姓名缩写来看了
❡ 变异凯撒
上面的 acsii 码值对比表可以看到 == 第一个字符向后移了 5,== 第二个向后移了 6, 第三个向后移了 7, 以此类推,很容易想到变异凯撒即每个向后移的位数是前一个加 1
❡ Quoted-printable
Quoted-printable 将任何 8-bit 字节值可编码为 3 个字符:一个等号 "=" 后跟随两个十六进制数字 (0–9 或 A–F) 表示该字节的数值。
例如,ASCII 码换页符(十进制值为 12)可以表示为 "=0C", 等号 "="(十进制值为 61)必须表示为 "=3D",gb2312 下 “中” 表示为 = D6=D0。除了可打印 ASCII 字符与换行符以外,所有字符必须表示为这种格式。
原文链接:https://blog.csdn.net/MikeCoke/article/details/105877373
❡ 篱笆墙的影子
❡ Rabbit
❡ RSA
python 代码
1 | |
❡ 丢失的 MD5
python 代码
1 | |
❡ Alice 与 Bob
在线分解质因数计算器工具 - 在线计算器 - 脚本之家在线工具
CTF 在线工具 - 哈希计算 | MD5、SHA1、SHA256、SHA384、SHA512、RIPEMD、RIPEMD160
❡ 大帝的密码武器
密文发现 C 为大写字母,而 C 移 13 位应该是大写 P,替换后,得到最终 flag。
❡ rsarsa
使用 RSA Tool2 工具解题
python 代码
1 | |
❡ Windows 系统密码
两个都用 Md5 试一下。
❡ 信息化时代的步伐
题目说结果为中文,结合 36(4x9)位的纯数字密文,猜测为中文电码解密。
电报码在线翻译(国际摩尔斯电码及中文电码) - 千千秀字
❡ 凯撒?替换?呵呵!
Quipqiup - Cryptoquip 和 Cryptogram 求解器


❡ 萌萌哒的八戒
binwalk 然后猪圈密码即可
❡ 权限获得第一步
❡ Misc
❡ 金三胖
使用随波逐流、StegSolve-FrameBrower
❡ 你竟然赶我走
使用 strings、随波逐流、010Editor 方法
❡ 二维码
可以使用 010Editor 或者是 strings 进行查看,发现里面还有文件,所以采用了修改后缀名为 zip 发现有密码,或者使用 Binwalk 进行也可以,然后使用 archar 或者 ziperllo 进行爆破,出来密码即可。
❡ 大白
❡ python 代码
1 | |
使用随波逐流或者 010Editor 进行修改宽高比
❡ wireshark
http && http.request.method == 「POST」
❡ 分析图片信息
❡ 乌镇峰会种图
strings 就行
❡ N 种方法解决
使用随波逐流工具
https://the-x.cn/encodings/Base64.aspx
❡ 基础破解
使用 archpr 工具即可,选数字
❡ 文件中的秘密
EXIF 信息.org:https://exifinfo.org](https://exifinfo.org/
❡ zip 伪加密
1 | |
一找 PK 头,二看标志位,奇改偶,伪加密解除

将 09 改为 00 即可
❡ 被嗅探的流量
❡ LSB
先单蓝后双红绿,三通道组合最后试
Alpha 通道碰不得,藏密必选 RGB
❡ 位平面选择原则(三句黄金口诀)
口诀①:「LSB 隐写 0 位藏,9 成题目在此方」 口诀②:「红绿蓝三原色,同步勾选效率强」 口诀③:「高位平面先别慌,特殊变形才要防」
为何只勾选 0 位? LSB 隐写本质是将数据藏在像素值二进制的最低位(第 0 位),如同把字写在纸的最边缘。 示例:像素值
255的二进制是11111111,修改第 0 位后变为11111110(差值仅 1,肉眼不可见)什么情况要勾选 1/2 位? 当题目明确提示 "高位隐写" 或常规 0 位无结果时(约占 CTF 题 10%),按以下优先级排查:
1
2
3
4
5
6# 位平面优先级顺序(覆盖99%题目)
priority = [
(0,0,0), # 红绿蓝0位(基础题)
(0,1,0), # 红0+绿1+蓝0(进阶组合)
(1,1,1) # 三通道1位(反套路题)
]
❡ rar
使用 archpr 工具即可,选数字
❡ qr
使用 qr serach 工具扫一下即可
❡ 镜子里面的世界
使用 steg 里面的 dataexract 选择三个 0 即可

❡ 爱因斯坦
binwalk -e 『/mnt/c/Users/HelloCTF_OS/Desktop/ 爱因斯坦 /misc2.jpg』
1 | |
❡ ningen
❡ 安装 Binwalk
1 | |
使用 BInwalk 提取,或者使用 010 删除前面保存 rar 然后密码破解即可
❡ 小明的保险箱
通过 ff d9 发现 rar
❡ easycap
通过追踪流查看
❡ 隐藏的钥匙
使用 strings 发现 flag 然后 Base64 解密即可
❡ 另外一个世界
ASCII 文本,十六进制,二进制,十进制,Base64 转换器
使用二进制解密即可
 s
s
❡ 数据包中的线索
通过追踪流发现有 = 号,判断可能是 base64, 但是过长考虑可能是图片转 base64 那么,需要通过网站并且添加头 ==“data:image/jpeg;base64,” 点击追加 img 标签 ==,
图片在线转换 base64 编码 - 在线 base64 编码转换成图片工具 (jsons.cn)](http://www.jsons.cn/img2base64/)
❡ 神秘龙卷风
BrainFuck 解密
❡ FLAG
使用 stegsolve 进行 rgb 查看,然后保存 1.zip, 因为是 pk 开头
❡ 假如给我三天光明

得到解压密码是 kmdonowg
Morse Code Audio Decoder
解码得:CTFWPEI08732?23D 换成 flag 还要换小写 flag
❡ 后门查杀
使用 D 盾或者火绒安全进行查找然后再找到对应的文件查看即可
❡ webshell 后门 (少 zp 文件)
❡ 来首歌吧
使用在线工具进行解密
MorseFM https://morsefm.com/ (支持 WAV/MP3 等格式,支持多语言,适合快速解码)
Morse Code Magic https://morsecodemagic.com/morse-code-audio-decoder/ (专注 WAV/MP3 解码,4 分钟音频 5 秒完成)
❡ 面具下的 flag
可以先用 strings 提取,但是需要对比两个找不同,发现少两个 + 号再解析不然出错
❡ 荷兰宽带数据泄露
NirSoft - freeware utilities: password recovery, system utilities, desktop utilities
搜索 username 或者 password,这可能是一个路由器配置文件 (bin),所以用到 RouterPassView 软件
❡ 九连环
通过随波逐流发现有伪加密,所以搜索 50 4B 01 02 修改
安装命令:sudo apt update && sudo apt install steghide
执行命令:steghide extract -sf 『/mnt/c/Users/HelloCTF_OS/Desktop/389a0c11-d0df-4180-829a-b529e6b0a1bc/_123456cry.jpg.extracted/asd/good - 已合并.jpg』
❡ 认真你就输了
随波逐流发现文件头是 zip 文件,要么修改文件要么 binwalk 就行
❡ 被偷走的文件
pcap 文件用 wireshark 并且发现 ftp-data 有 rar 文件进行到处对象导出即可。
导出文件三种方法:
- 到处对象
- 追踪流然后原始数据导出即可
- 导出字节流
❡ 被劫持的神秘礼物
使用 wireshark 发现 ==(application/x-www-form-urlencoded)==,之后根据题意找到账号密码拼接,使用如下命令即可。
1 | |
❡ 藏藏藏
打开 010 发现 pk 删除前面所有内容保存 zip 解压后扫码即可
❡ 佛系青年
伪加密修改后查看 fo.txt 底下那句话使用随波逐流解密即可
❡ 你猜我是个啥
使用 strings 查看即可
❡ 秘密文件
筛选后发现有 ftp 优先查看,发现里面有 rar 文件,还有一点其实随波逐流里面也可以直接查看并且通过分离破解即可获取 flag.
❡ 刷新过的图片
1 | |
题目说 “刷新过的图片”,结合键盘上刷新键为 F5 可判断此题为 F5 隐写,运用工具 F5-steganography 可以对其中的内容进行提取
项目首页 - F5-steganography:F5 steganography - GitCode
cd F5-steganography-master
java Extract 『/mnt/c/Use
rs/HelloCTF_OS/Desktop/a05ed035-b476-49d6-9b32-462ff13c5944/Misc.jpg』
❡ 鸡你太美
发现缺少 gif 头,47 49 46 38.
❡ just_a_rar
破解密码然后查看 exif 信息即可
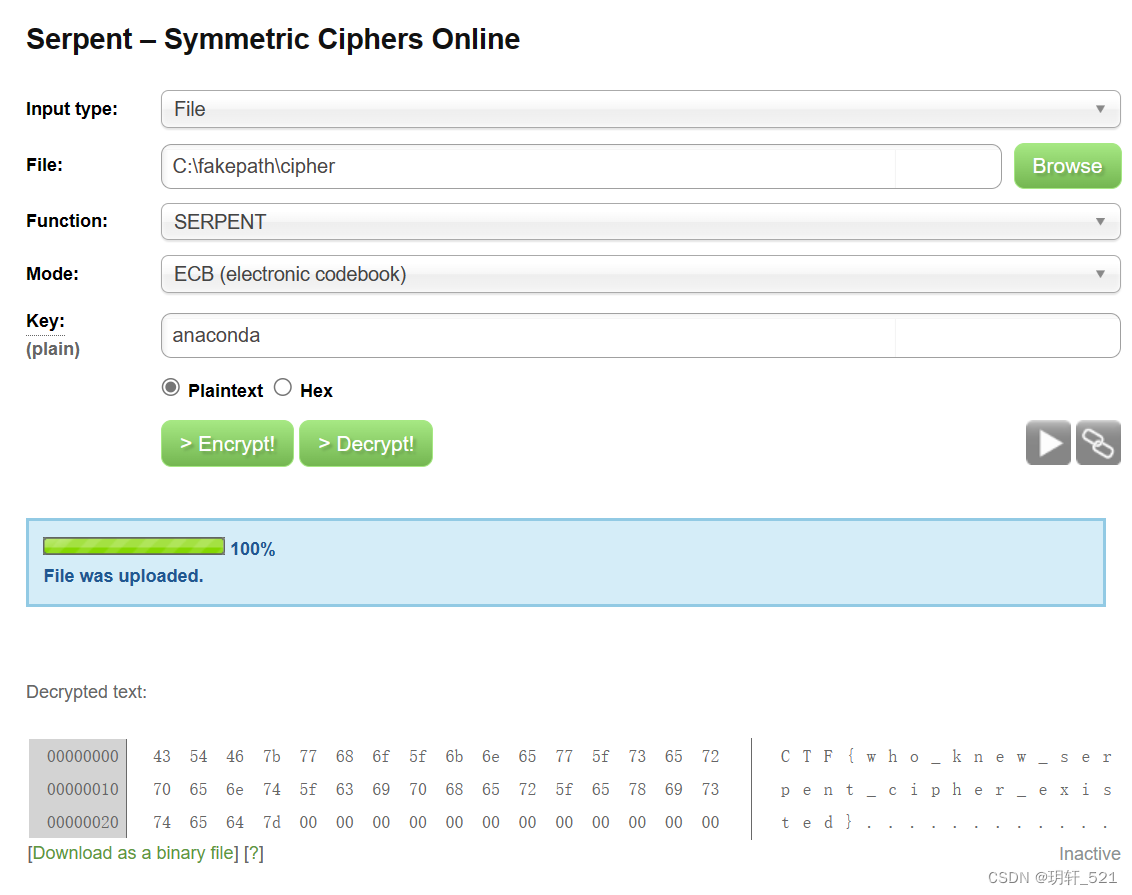
❡ snake (原先的网站没有了,所以解析不了)
1 | |
Serpent Encryption – Easily encrypt or decrypt strings or files
❡ 菜刀 666
菜刀使用 http.request.methodPOST,并且查看 z1 和 z2,发现 z2 有 FF D8 是 jpg 导入 010 发现密码,然后解压即可
❡ 一叶障目
可以使用之前的 Python 脚本或者随波逐流即可
❡ 纳尼
如果 git 分帧查看不了,那么就用 stegsolve 的 framebrower 来查看即可。
❡ 神奇的二维码
Python 代码
1 | |
粗线条是 - , 细线条是 .
❡ excel 破解
使用 strings 或者随波逐流查看即可
❡ 来题中等的吧
粗细记录摩斯密码即可
❡ 谁赢了比赛?
使用 Binwalk 进行分离并且破解密码,之后使用 qcr 进行二维码解析
❡ [ACTF 新生赛 2020] outguess
发现 exif 再通过社会主义解密,然后通过题目猜测发现是 outguess,通过一下密码解密
1 | |
outguess -k 『abc』 -r 『/mnt/c/Users/HelloCTF_OS/Desktop/attachment/tmp/huhuhu/mmm.jpg』 『/mnt/c/Users/HelloCTF_OS/Desktop/attachment/tmp/huhuhu/flag.txt』
❡ 梅花香之苦寒来
使用 gnuplot 画图即可
生成文本后使用 plot xxx.
python 代码
1 | |
❡ [WUSTCTF2020] find_me(在线网站打不开)
使用 exiftool xxx,然后盲文在线加解密:https://www.qqxiuzi.cn/bianma/wenbenjiami.php?s=mangwen
1 | |

❡ 穿越时空的思念
之前使用静音删除左声道,单声道导出右声道 wav 使用在线网站但是解析有些许错误,所以使用手动解析
❡ [GUET-CTF2019]KO
使用 brainfuck 解密即可
❡ [ACTF 新生赛 2020] base64 隐写
python 代码
1 | |
❡ [SWPU2019] 我有一只马里奥

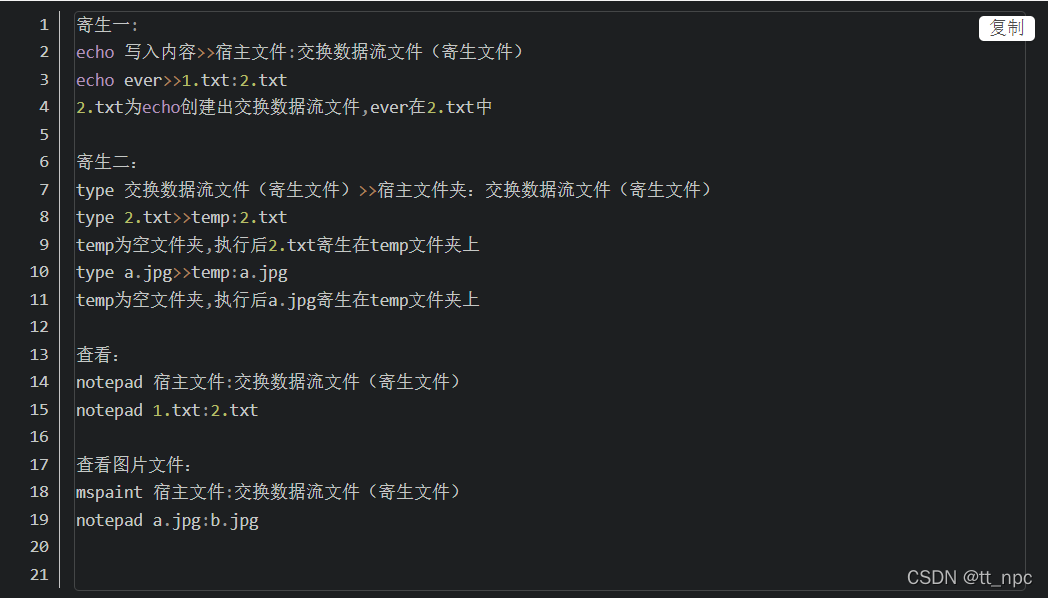
notepad 1.txt:flag.txt
使用工具 NtfsStreamsEditor 或 AlternateStreamView 打开存放 1.txt 文件的文件夹,扫描出现隐藏文件文件,导出后打开,得到 flag。
AlternateStreamView (跳转页面后,向下滑动,下载对应的 32 或 64 位软件)
❡ [MRCTF2020]ezmisc
修改宽高
❡ [GXYCTF2019]gakki
python 代码
1 | |
❡ [HBNIS218]caesar
python 代码
1 | |
随波逐流
❡ [SUCTF2018]single dog
aaencode 编码
❡ 黑客帝国
导入十六进制,然后发现打开不了,换成 jpg 头,也就是 FF D8 4A46 之前的删除掉
❡ [HBNIS2018] 低个头
键盘按键
❡ [SWPU2019] 伟大的侦探
使用 010 Editor 打开密码.txt 文件,选择编辑方式为 EBCDIC (B),找到明文密码
之后对照跳舞的小人即可
[BUUCTF SWPU2019] 伟大的侦探 1 - 阿里云开发者社区
❡ [MRCTF2020] 你能看懂音符吗
修改 62 51 为 51 62 然后保存解压,之后发现 Binwalk 有文件,之后 document.xml 里查到音符,使用芊芊秀字(但是失效了)就可以了。
❡ 我吃三明治
foremost -i /mnt/c/Users/HelloCTF_OS/Desktop/attachment/flag.jpg, 发现有两张图片,但是打开还是之前的那张,通过题解发现 FF D8 是开头,FF D9 是结尾,在 FF D8 和 FF D9 之间有信息。

❡ [ACTF 新生赛 2020] NTFS 数据流
跟之前的一道题类似使用 alternatestreamview-x64 打开文件在导出即可。
❡ [SWPU2019] 你有没有好好看网课?
使用数字发现四位不够,一位位加到 6 位即可,

使用 kinovea 软件,根据图片说的 5.20 和 7.11 其实是 5.67 左右在灯上出现内容,然后第一处为敲击码
CTF 在线工具 - 在线敲击码 | 敲击码编码 | 敲击码算法 | tap code
基于 5×5 方格波利比奥斯方阵来实现的,不同点是是用 K 字母被整合到 C 中,因此密文的特征为 1-5 的两位一组的数字,编码的范围是 A-Z 字母字符集,字母不区分大小写。..... ../... ./... ./... ../
解码方法: 每组 / 分隔的符号对应一个字母,例如:
..... ..→ 第 5 行第 2 列 → W... .→ 第 3 行第 1 列 → L- 完整密文
WLLM→ 转为小写wllm



也可以通过 52313132 来解码,就是数点即可。

然后根据 7.37 时候发现编码


之后拼接起来两个解码信息进行解压,然后使用 strings 或者随波逐流即可查看信息.
扩展知识:
查询多个信息
逻辑或
strings xxx | grep -iE 「flag|ctf」
-i:忽略大小写-E:启用扩展正则表达式,允许使用|符号分隔多个模式
逻辑与
strings xxx | grep -i 「flag」 | grep -i 「ctf」
查找并显示头尾匹配结果
1 | |
结合十六进制查看工具 如果需要分析二进制文件的特定偏移:
1 | |
xxd:生成十六进制和 ASCII 表示
hexdump -C:经典格式的十六进制转储
❡ sqltest
1 | |
python 代码
1 | |
❡ [UTCTF2020]docx
进行 Binwalk 然后再 media 一张张图 png 查看信息

❡ john-in-the-middle
先用导出对象发现很多图片,逐个使用 stegsolve 发现有信息

扩展知识:
zsteg 功能:支持 LSB 隐写、zlib 压缩数据、OpenStego 等检测,常用于 CTF 比赛的图片隐写分析
1 | |
❡ [ACTF 新生赛 2020] swp
发现 zip 文件导出然后使用 strings 查看即可
❡ [GXYCTF2019]SXMgdGhpcyBiYXNlPw==
python 代码
1 | |
❡ 间谍启示录
使用 foremost 然后用 tree 发现文件,重要的是开启隐藏的文件,机密文件查看即可。

❡ 小易的 U 盘
使用修改后缀名或者是 foremost 查看,然后根据 strings 或者使用 IDA 查看也行。
1 | |


❡ 喵喵喵
使用 zsteg 查看然后使用 stegsolve 进行 lsb 隐写保存图片之后修改宽高,使用 QR 进行查看链接下载,注意的是得用 winrar 解压才行,不然 NTFS 查看不到,然后使用 pyc 反编译,使用脚本。
pyc 反编译:https://tool.lu/pyc/
python 代码
1 | |
❡ [WUSTCTF2020] 爬
使用 file 文件查看后缀名,然后转换 word 删除图片,使用十六进制转字符查看即可。
https://www.bejson.com/convert/ox2str/